Advancements and Complexities in Clustering for Large Language Models in Machine Learning
In the ever-evolving field of machine learning (ML), clustering has remained a fundamental technique used to discover inherent structures in data. However, when it comes to Large Language Models (LLMs), the application of clustering presents unique challenges and opportunities for deep insights. In this detailed exploration, we delve into the intricate world of clustering within LLMs, shedding light on its advancements, complexities, and future direction.
Understanding Clustering in the Context of LLMs
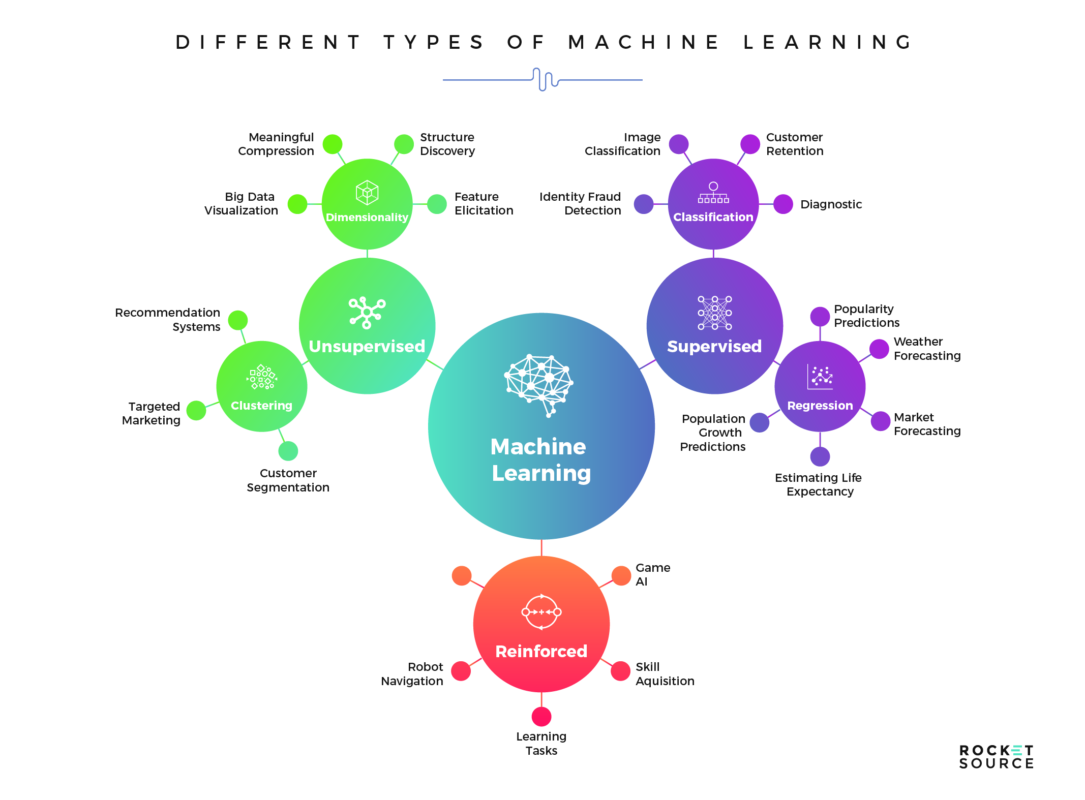
Clustering algorithms are designed to group a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups. In the context of LLMs, clustering helps in understanding the semantic closeness of words, phrases, or document embeddings, thus enhancing the models’ ability to comprehend and generate human-like text.
Techniques and Challenges
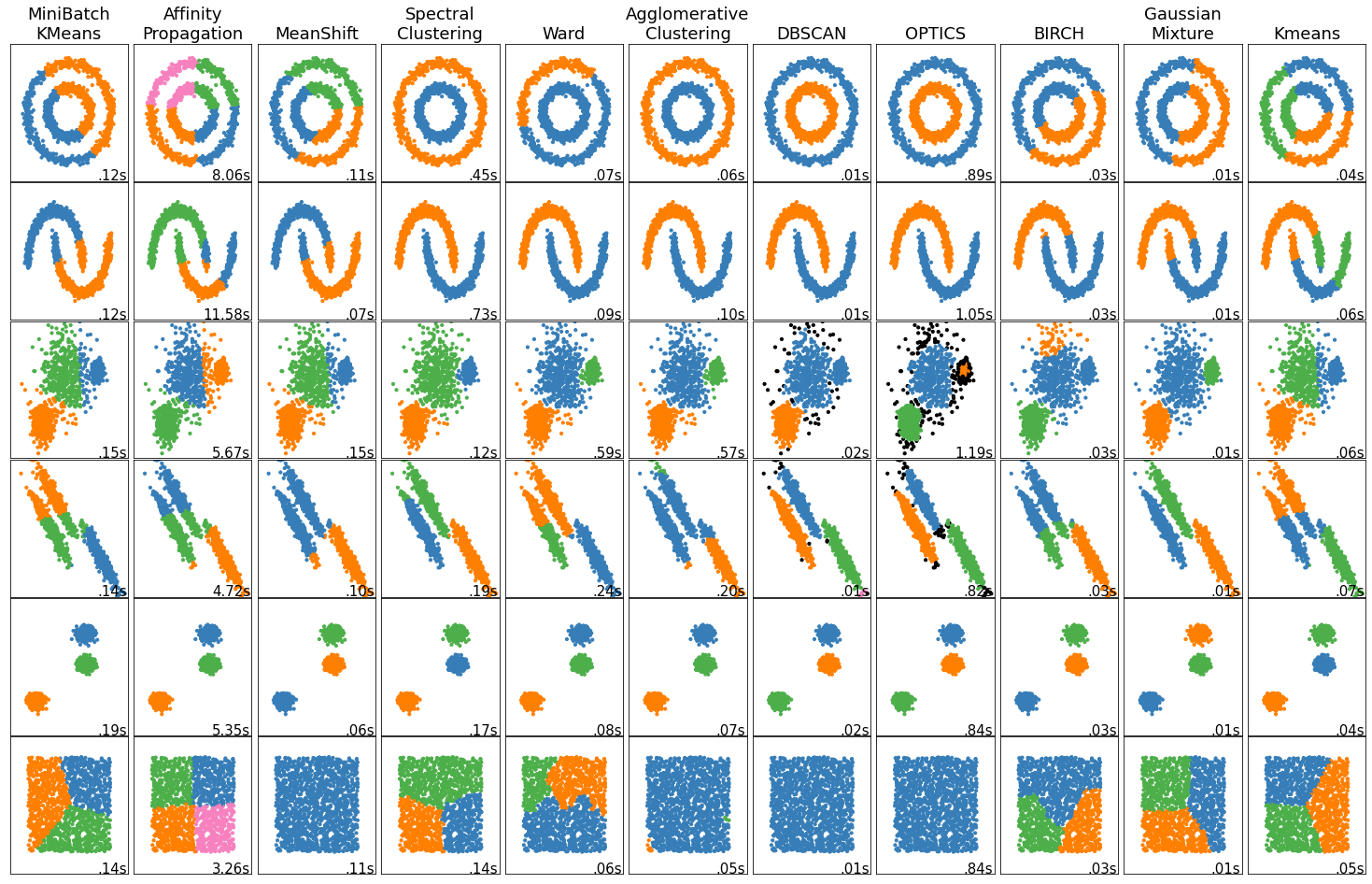
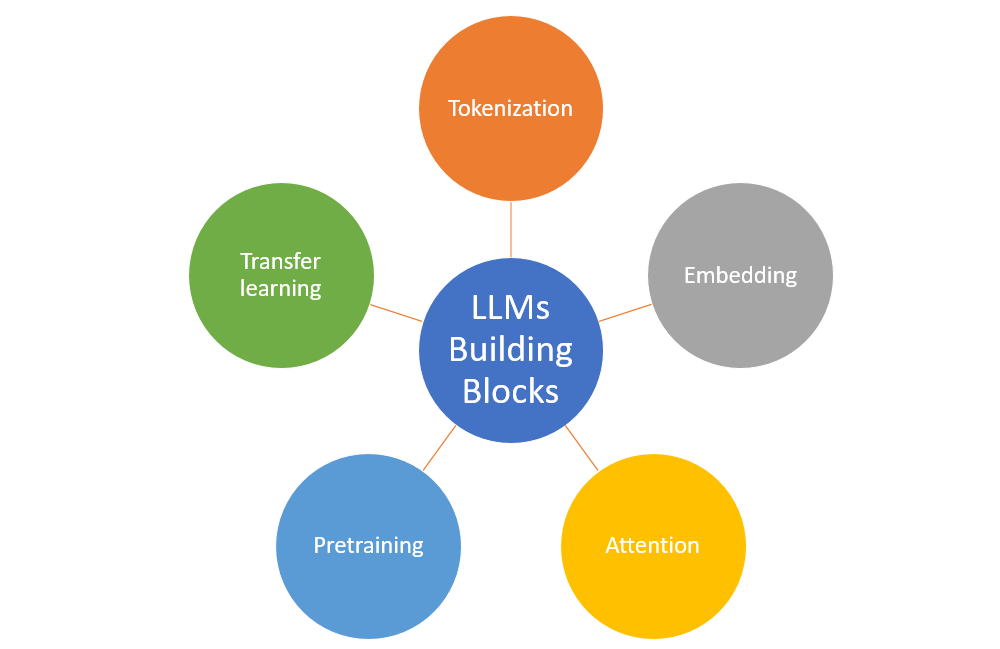
LLMs such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) have pushed the boundaries of what’s possible with natural language processing. Applying clustering in these models often involves sophisticated algorithms like k-means, hierarchical clustering, and DBSCAN (Density-Based Spatial Clustering of Applications with Noise). However, the high dimensionality of data in LLMs introduces the ‘curse of dimensionality’, making traditional clustering techniques less effective.
Moreover, the dynamic nature of language, with its nuances and evolving usage, adds another layer of complexity to clustering within LLMs. Strategies to overcome these challenges include dimensionality reduction techniques and the development of more robust, adaptive clustering algorithms that can handle the intricacies of language data.
Addressing Bias and Ethics
As we navigate the technical complexities of clustering in LLMs, ethical considerations also come to the forefront. The potential for these models to perpetuate or even amplify biases present in the training data is a significant concern. Transparent methodologies and rigorous validation protocols are essential to mitigate these risks and ensure that clustering algorithms within LLMs promote fairness and diversity.
Case Studies and Applications
The use of clustering in LLMs has enabled remarkable advancements across various domains. For instance, in customer service chatbots, clustering can help understand common customer queries and sentiments, leading to improved automated responses. In the field of research, clustering techniques in LLMs have facilitated the analysis of large volumes of scientific literature, identifying emerging trends and gaps in knowledge.
Another intriguing application is in the analysis of social media data, where clustering can reveal patterns in public opinion and discourse. This not only benefits marketing strategies but also offers insights into societal trends and concerns.
Future Directions
Looking ahead, the integration of clustering in LLMs holds immense potential for creating more intuitive, context-aware models that can adapt to the complexities of human language. Innovations such as few-shot learning, where models can learn from a minimal amount of data, are set to revolutionize the efficiency of clustering in LLMs.
Furthermore, interdisciplinary approaches combining insights from linguistics, cognitive science, and computer science will enhance our understanding and implementation of clustering in LLMs, leading to more natural and effective language models.
In Conclusion
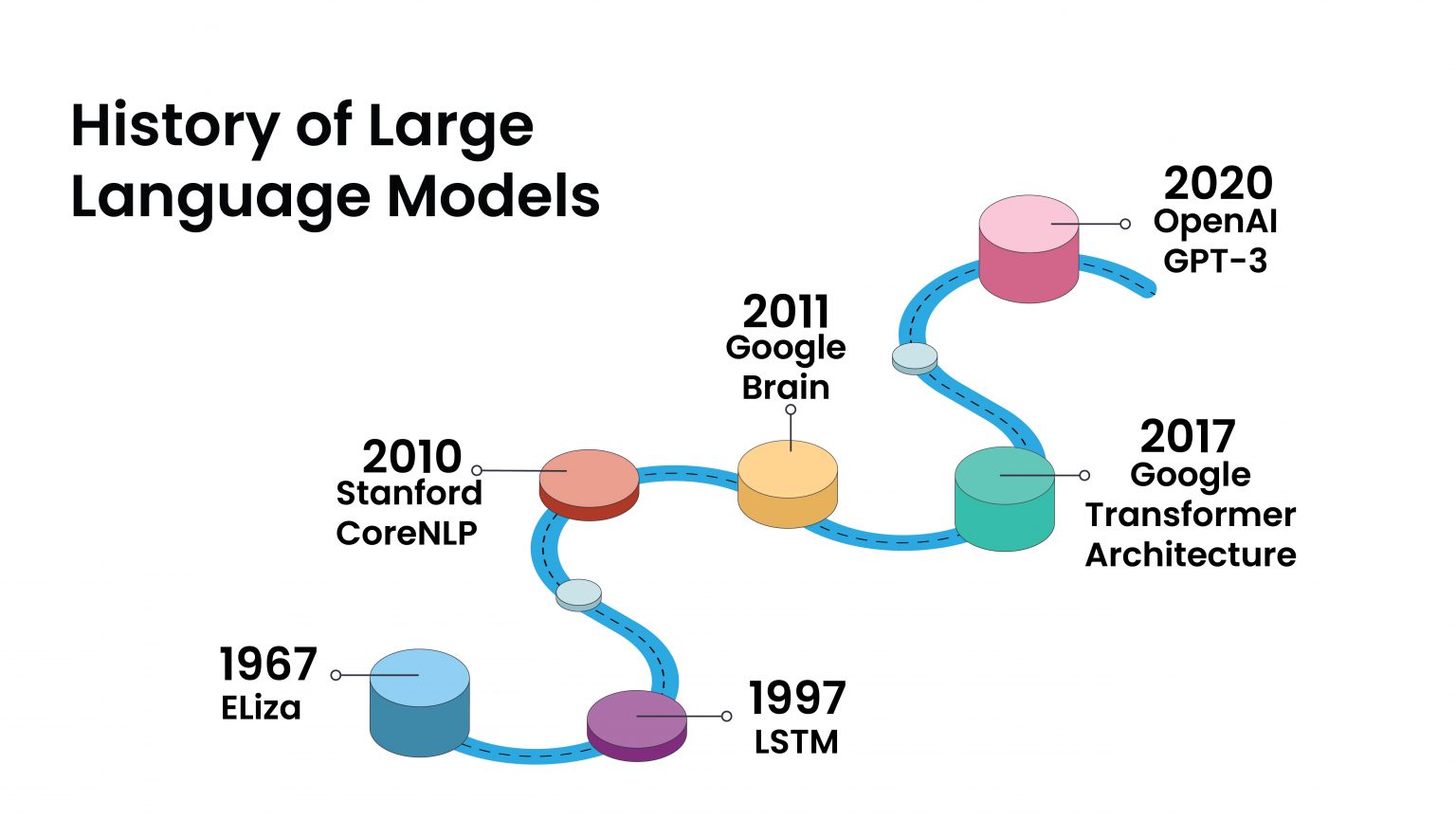
In the detailed exploration of clustering within Large Language Models, we uncover a landscape filled with technical challenges, ethical considerations, and promising innovations. As we forge ahead, the continuous refinement of clustering techniques in LLMs is essential for harnessing the full potential of machine learning in understanding and generating human language.
Reflecting on my journey from developing machine learning algorithms for self-driving robots at Harvard University to applying AI in real-world scenarios through my consulting firm, DBGM Consulting, Inc., it’s clear that the future of clustering in LLMs is not just a matter of technological advancement but also of thoughtful application.
Embracing the complexities and steering towards responsible and innovative use, we can look forward to a future where LLMs understand and interact in ways that are increasingly indistinguishable from human intelligence.
< >
>
< >
>
< >
>
Focus Keyphrase: Clustering in Large Language Models
 >
> >
> >
>