Advancing Frontiers in Machine Learning: Deep Dive into Dimensionality Reduction and Large Language Models
In our continuous exploration of machine learning, we encounter vast arrays of data that hold the key to unlocking predictive insights and transformative decision-making abilities. However, the complexity and sheer volume of this data pose significant challenges, especially in the realm of large language models (LLMs). This article aims to dissect the intricate relationship between dimensionality reduction techniques and their critical role in evolving LLMs, ensuring they become more effective and efficient.
Understanding the Essence of Dimensionality Reduction
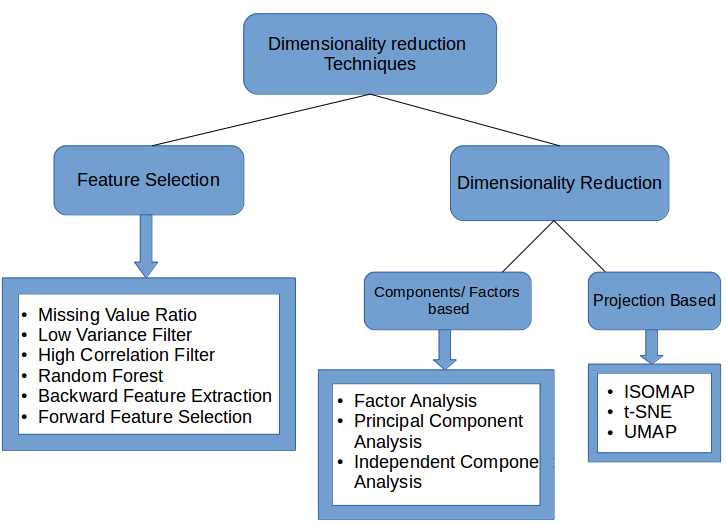
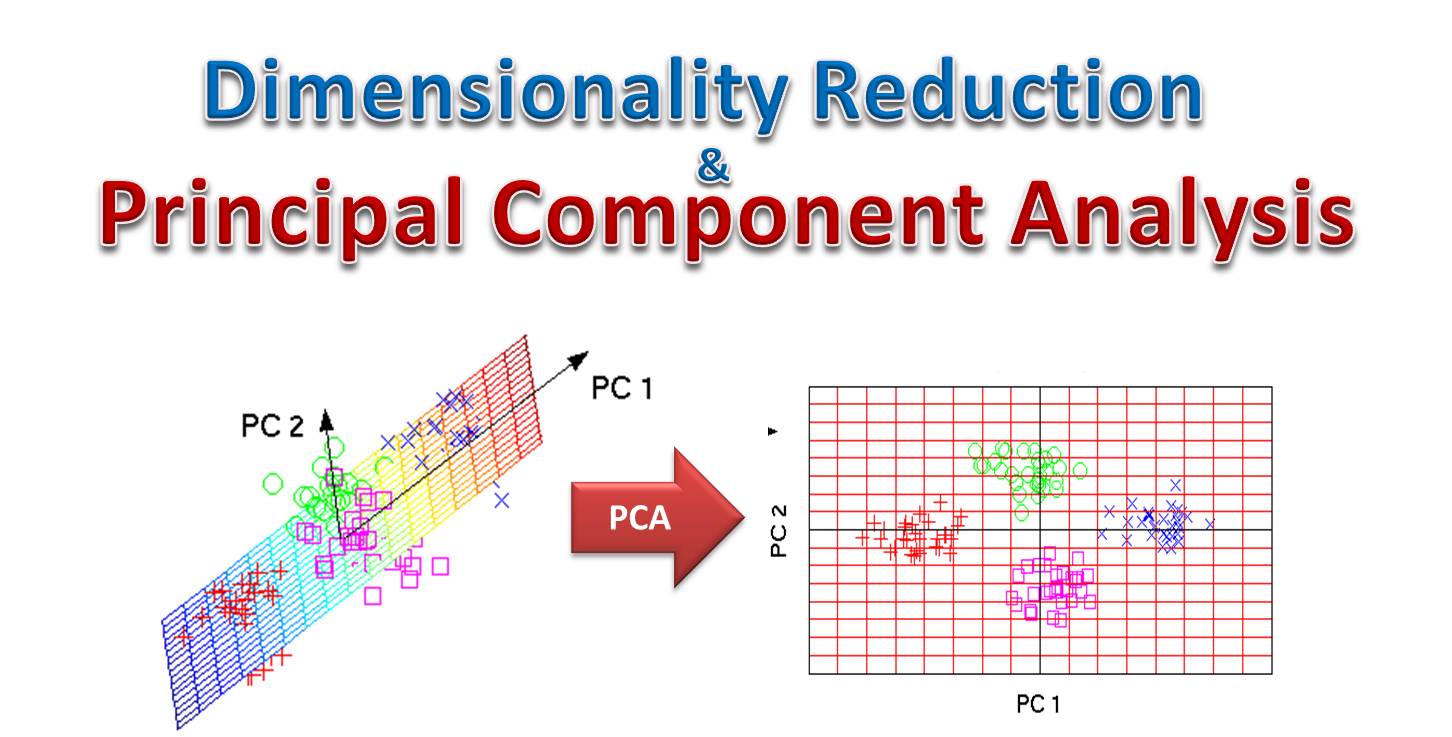
Dimensionality reduction, a fundamental technique in the field of machine learning, involves simplifying the amount of input variables under consideration, to streamline data processing without losing the essence of the information. The process can significantly enhance the performance of LLMs by reducing computational overheads and improving the models’ ability to generalize from the training data.
< >
>
Core Techniques and Their Impact
Several key dimensionality reduction techniques have emerged as pivotal in refining the structure and depth of LLMs:
- Principal Component Analysis (PCA): PCA transforms a large set of variables into a smaller one (principal components) while retaining most of the original data variability.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is particularly useful in visualizing high-dimensional data in lower-dimensional space, making it easier to identify patterns and clusters.
- Autoencoders: Deep learning-based autoencoders learn compressed, encoded representations of data, which are instrumental in denoising and dimensionality reduction without supervised data labels.
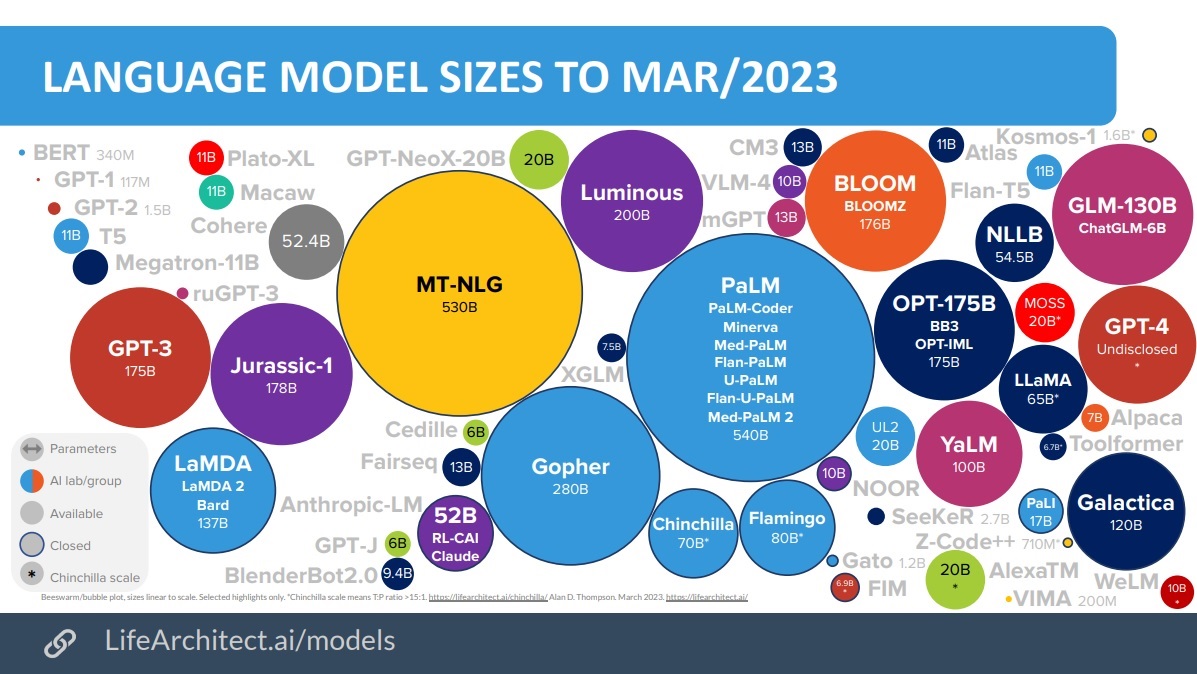
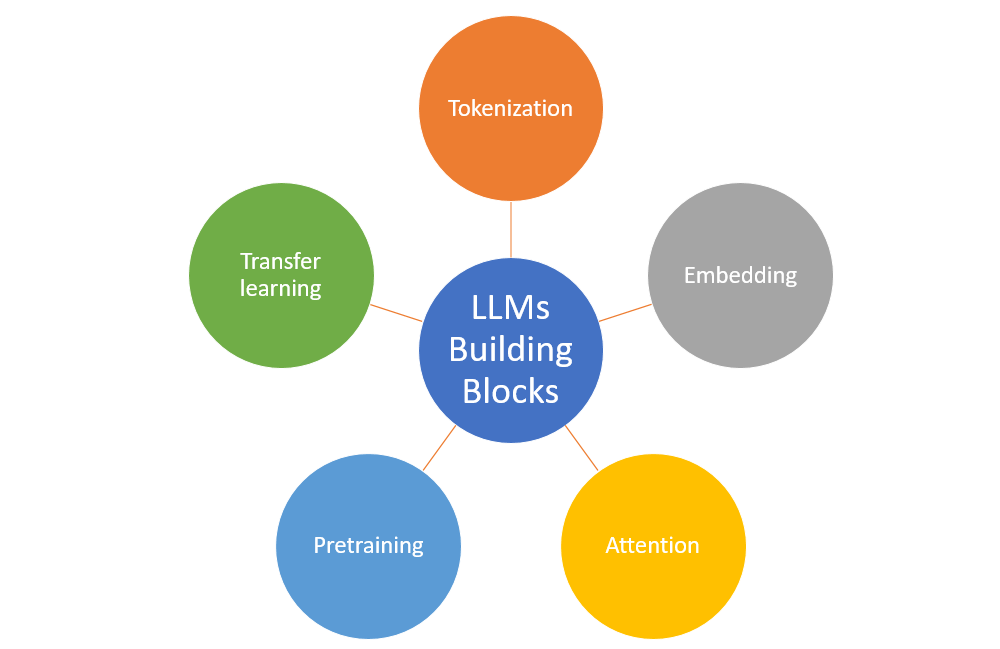
Advancing Large Language Models Through Dimensionality Reduction
Large Language Models have become the backbone of modern AI applications, from automated translation to content generation and beyond. The synthesis of dimensionality reduction into LLMs not only enhances computational efficiency but also significantly improves model performance by mitigating issues related to the curse of dimensionality.
< >
>
Case Studies: Dimensionality Reduction in Action
Integrating dimensionality reduction techniques within LLMs has shown remarkable outcomes:
- Improved language understanding and generation by focusing on relevant features of the linguistic data.
- Enhanced model training speeds and reduced resource consumption, allowing for the development of more complex models.
- Increased accuracy and efficiency in natural language processing tasks by reducing the noise in the training datasets.
These advancements advocate for a more profound integration of dimensionality reduction in the development of future LLMs, ensuring that these models are not only potent but also resource-efficient.
Looking Ahead: The Future of LLMs with Dimensionality Reduction
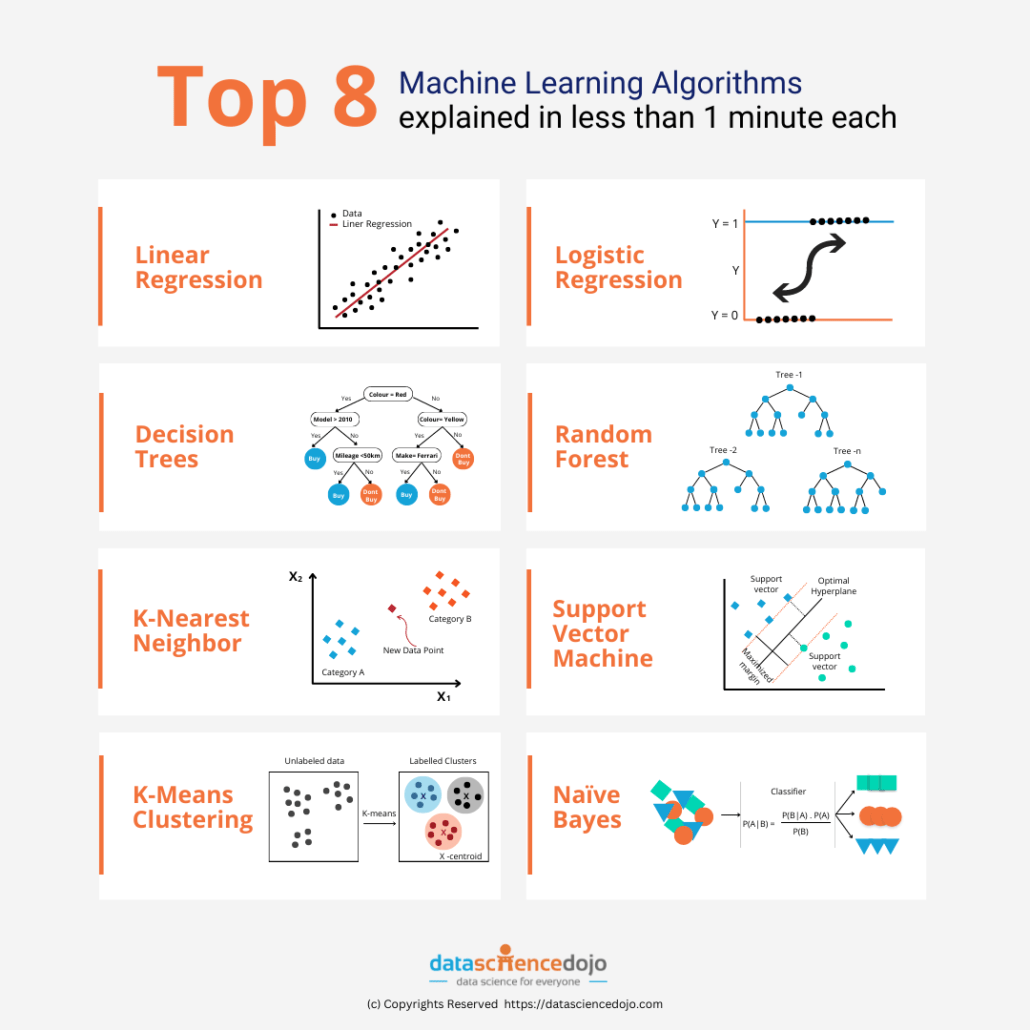
The journey of LLMs, guided by dimensionality reduction, is poised for exciting developments. Leveraging my background in artificial intelligence, particularly in the deployment of machine learning models, and my academic focus at Harvard University, it is evident that the combination of advanced machine learning algorithms and dimensionality reduction techniques will be crucial in navigating the complexities of enormous datasets.
As we delve further into this integration, the potential for creating more adaptive, efficient, and powerful LLMs is boundless. The convergence of these technologies not only spells a new dawn for AI but also sets the stage for unprecedented innovation across industries.
< >
>
Connecting Dimensions: A Path Forward
Our exploration into dimensionality reduction and its symbiotic relationship with large language models underscores a strategic pathway to unlocking the full potential of AI. By understanding and applying these principles, we can propel the frontier of machine learning to new heights, crafting models that are not only sophisticated but also squarely aligned with the principles of computational efficiency and effectiveness.
In reflecting on our journey through machine learning, from dimensionality reduction’s key role in advancing LLMs to exploring the impact of reinforcement learning, it’s clear that the adventure is just beginning. The path forward promises a blend of challenge and innovation, driving us toward a future where AI’s capabilities are both profoundly powerful and intricately refined.
Concluding Thoughts
The exploration of dimensionality reduction and its interplay with large language models reveals a promising avenue for advancing AI technology. With a deep background in both the practical and theoretical aspects of AI, I am keenly aware of the importance of these strategies in pushing the boundaries of what is possible in machine learning. As we continue to refine these models, the essence of AI will evolve, marking a new era of intelligence that is more accessible, efficient, and effective.
Focus Keyphrase: Dimensionality reduction in Large Language Models
 >
> >
> >
> >
> >
> >
>