Transform Your Data Science Workflow with QueryPanda for Efficient Data Handling

Introducing QueryPanda: A Novel Toolkit for Efficient Data Handling in Machine Learning Projects
In the fast-paced world of data science and machine learning, the efficiency of data handling and preprocessing is paramount. My journey through the realms of artificial intelligence, cloud solutions, and the profound intricacies of machine learning models during my tenure at DBGM Consulting, Inc. and academic pursuit at Harvard University, has instilled in me an appreciation for tools that streamline these processes. It’s with great enthusiasm that I introduce QueryPanda, a project recently added to PyPI that promises to revolutionize the way data scientists interact with PostgreSQL databases.
Understanding QueryPanda’s Core Offerings
QueryPanda is not just another toolkit; it’s a comprehensive solution designed to simplify data retrieval, saving, and loading, thus significantly reducing the time data scientists spend on data preparation activities. Let’s dive into its features:
- Customizable Query Templates: Retrieve data from PostgreSQL databases efficiently, tailoring queries to your precise needs.
- Diverse Data Saving Formats: With support for CSV, PKL, and Excel formats, and the implementation of checkpointing, long-running data tasks become manageable.
- Seamless Integration with Pandas: Load datasets directly into pandas DataFrames from various file formats, easing the transition into data analysis and machine learning modeling.
- Modular Design: Its architecture promotes easy integration into existing data processing pipelines, augmenting workflow productivity.
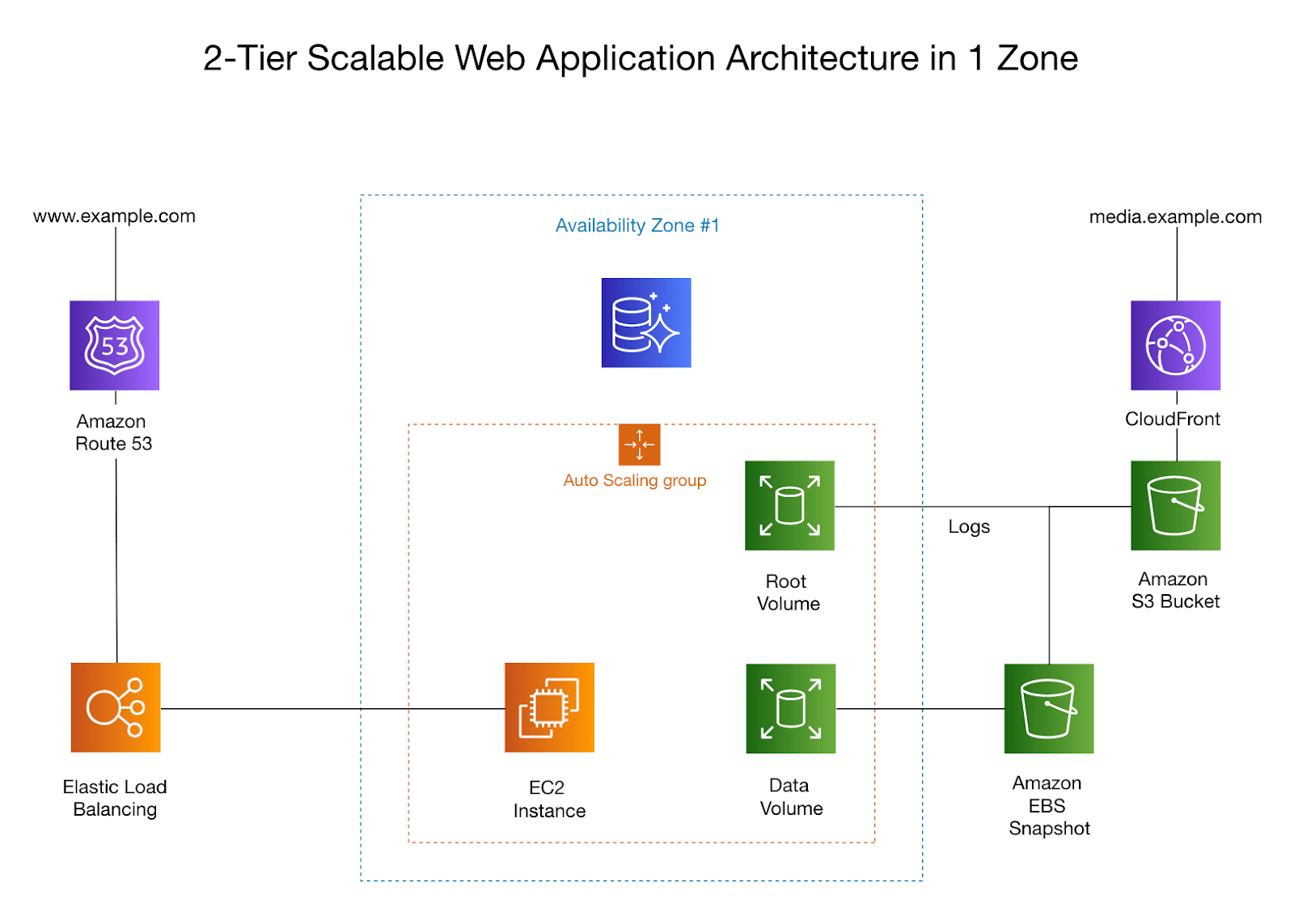
Getting Started with QueryPanda
Installation is straightforward for those familiar with Python, and the project recommends using Python 3.8 or higher for optimal performance. After cloning the repository from GitHub, users are guided to install necessary dependencies and configure their database connections through a simple JSON file.
The toolkit’s design emphasizes flexibility and user-friendliness, ensuring that data scientists can start leveraging its capabilities with minimal setup.
Real-World Applications and Impact
The introduction of QueryPanda into the data science toolkit arsenal is timely. Considering the increasing complexities and volumes of datasets, tools that can reduce preprocessing time are invaluable. In my previous articles, like Revolutionizing ML Projects: The Power of Query2DataFrame Toolkit, I explored how efficient data handling could significantly impact machine learning projects. QueryPanda extends this narrative by offering a more refined, database-centric approach to data handling.
By streamlining the initial stages of data preparation, QueryPanda not only accelerates the development of machine learning models but also enhances the accuracy of data analysis. This is particularly relevant in applications requiring real-time data retrieval and processing, where the toolkit’s checkpointing feature can be a game-changer.
Conclusion
Incorporating QueryPanda into your data science projects represents a strategic move towards heightened efficiency and productivity. Its focus on easing the data handling processes aligns with the broader goal of making AI and machine learning more accessible and effective. As someone deeply embedded in the intricacies of AI development and analytics, I see immense value in embracing such tools that simplify and enhance our work.
For those interested in contributing to the project, QueryPanda welcomes collaboration, underlining the open-source community’s spirit of collective innovation. I encourage you to explore QueryPanda and consider how it can fit into and elevate your data science workflows.
To delve deeper into QueryPanda and start leveraging its powerful features, visit the project page on GitHub. Embrace the future of efficient data handling in machine learning with QueryPanda.
Focus Keyphrase: Efficient Data Handling in Machine Learning Projects








Having read your article, I’m cautiously optimistic about QueryPanda. The toolkit seems promising, especially for someone like me who is always looking for ways to improve efficiency in projects. I have to admit, I’m slightly skeptical about how it will handle very large datasets, given my past experiences with other tools underperforming. However, your thorough explanation and clear passion for this project are definitely persuading me to give it a try. I appreciate the innovation in this space, and I’m hopeful about the potential time savings and efficiency gains. Also, it’s refreshing to hear from someone who understands the intricacies of the field.
I’m truly excited to share my latest work on QueryPanda, a toolkit born out of my experiences and challenges in data handling within AI and machine learning spaces. This tool promises to transform tedious data management tasks into simple, efficient processes. My goal with this article and QueryPanda is to support the data science community by offering a robust solution that streamlines data manipulation tasks, making our work more impactful and enjoyable. Let’s embrace the next level of efficiency together!