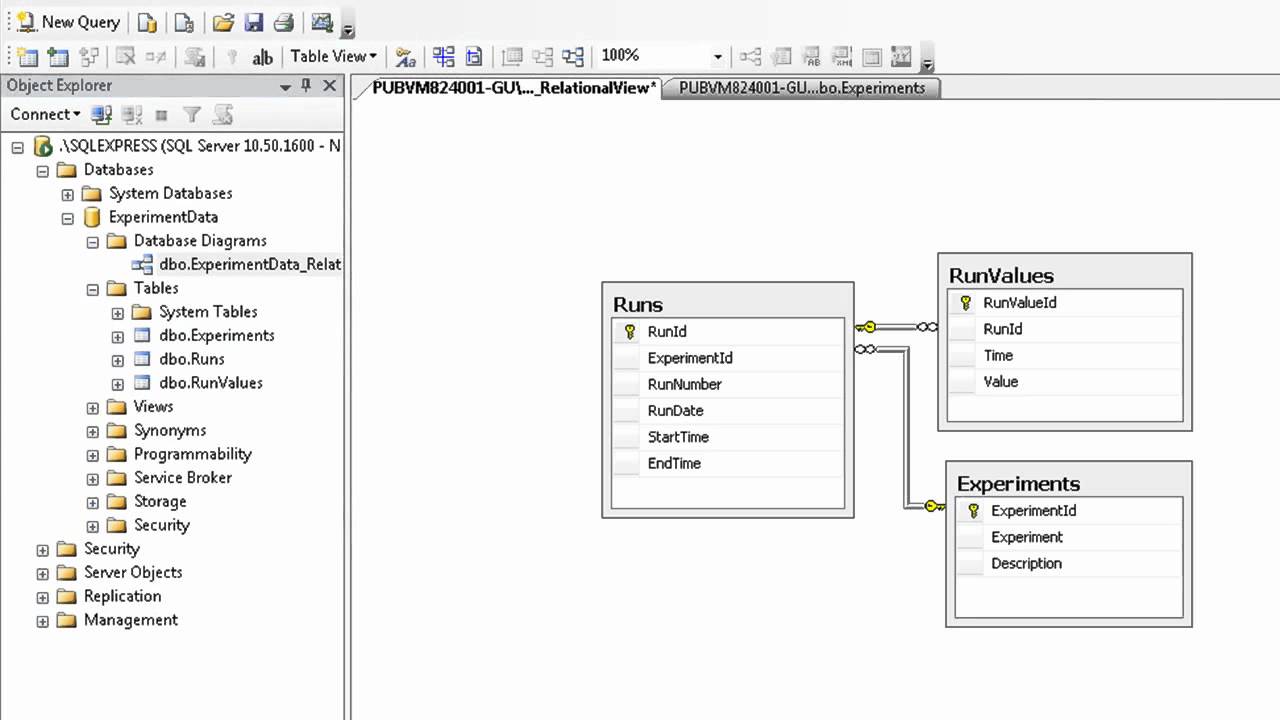
We will look at the creation of a Migration Factory – a scaled team (often offshore or outsourced) that drives large-scale migration of enterprise applications to the cloud. Google Cloud has a four-stage approach to Migration, Discover/Assess, Plan, Migrate and Optimize, and the Migration Factory is designed to help execute the Migrate stage. We also discussed these four migration phases here in Migrate Enterprise Workloads to Google Cloud.
You should have a high-level understanding of the concepts discussed in the Google Cloud Adoption Framework, and have a desire to migrate a large number of workloads to Google Cloud (in the order of hundreds or more of applications, or thousands or more of servers).
Overview
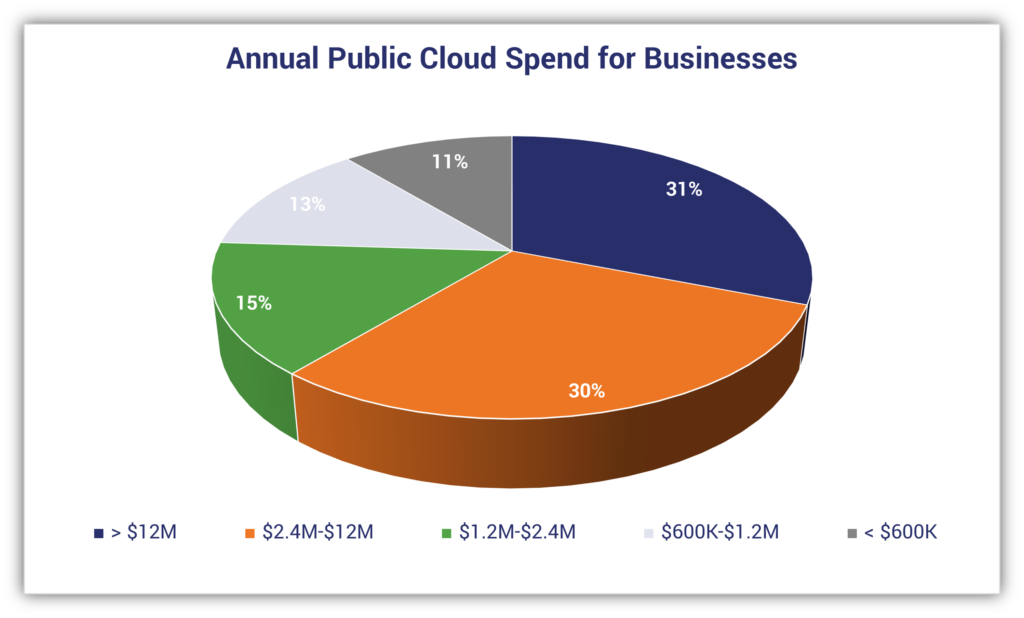
Many of you are looking to GCP to solve your on-premises infrastructure challenges. These could be capacity constraints, aging hardware, or reliability issues; or alternatively, you may be looking to capitalize on the value that cloud infrastructure can bring – saving money through automatic scaling, or deriving business value from large scale, cloud-native approaches to data processing and analytics.
With that said, moving to the cloud can be a complex and time-consuming journey. An inefficient migration program can significantly reduce the benefits realized from the migration, and a pure lift-and-shift approach can leave you with similar challenges and costs in the cloud as you were trying to escape from on-premises.
If you have already started this journey, you might find it harder than expected – with more than half of migration projects being delayed or over budget. Some typical challenges are:
- Unclear goals
- Lack of sponsorship
- Poor planning
- Wrong technology choice
- Delivery capability and operating model
Migration Approach
Google Cloud Adoption Framework
When migrating to Google Cloud, it is the recommended to use the Google Cloud Adoption Framework when establishing the foundational aspects of a cloud migration program. Let’s review some of that again here.
There are three components of the framework Google Cloud uses to help you get to the cloud:
- Three Maturity Phases (applied to the Four Adoption Themes)
- Tactical– You have individual workloads in place but no solid plan bringing them all together with a strategy that builds out towards the future.
- Strategic– You have a broader vision that brings together the individual workloads which are designed and developed with a concern for future needs and scale.
- Transformational– With your cloud operations now functioning smoothly, you are integrating data and insights learned from working now in the cloud.
- Four Adoption Themes
- Learn – The value and scale of your learning programs that you have in place to enhance to skillset of your technical teams. It also refers to your ability to supplement your technical teams with the right partners.
- Lead – The degree to which your technical teams are supported from leadership to migrate to the cloud. Additionally, we need to consider how cross-functional, collaborative, and self-motivated these teams are.
- Scale – The degree to which you will use cloud-native services which will reduce operational overhead and automate manual processes and polices.
- Secure– Your capacity to protect your cloud services from unauthorized access using a multilayered, identity-centric security model.
- Epics
- The scope and structure of the program you will use for cloud adoption can be broken into workstreams, which Google refers to as epics. Epics are designed to not overlap one another, are aligned to manageable groups of stakeholders and can be further broken down into induvial user stories.
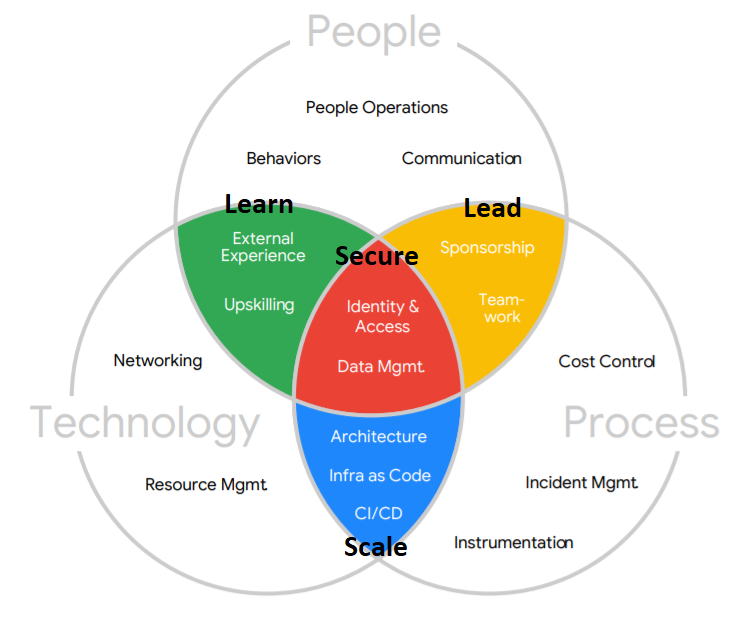
Migration Journey
Once you have assessed your migration journey with the Cloud Adoption Framework, part of that framework is to assess your Cloud Maturity. This will help you build a migration path, such as this one the migration factory:
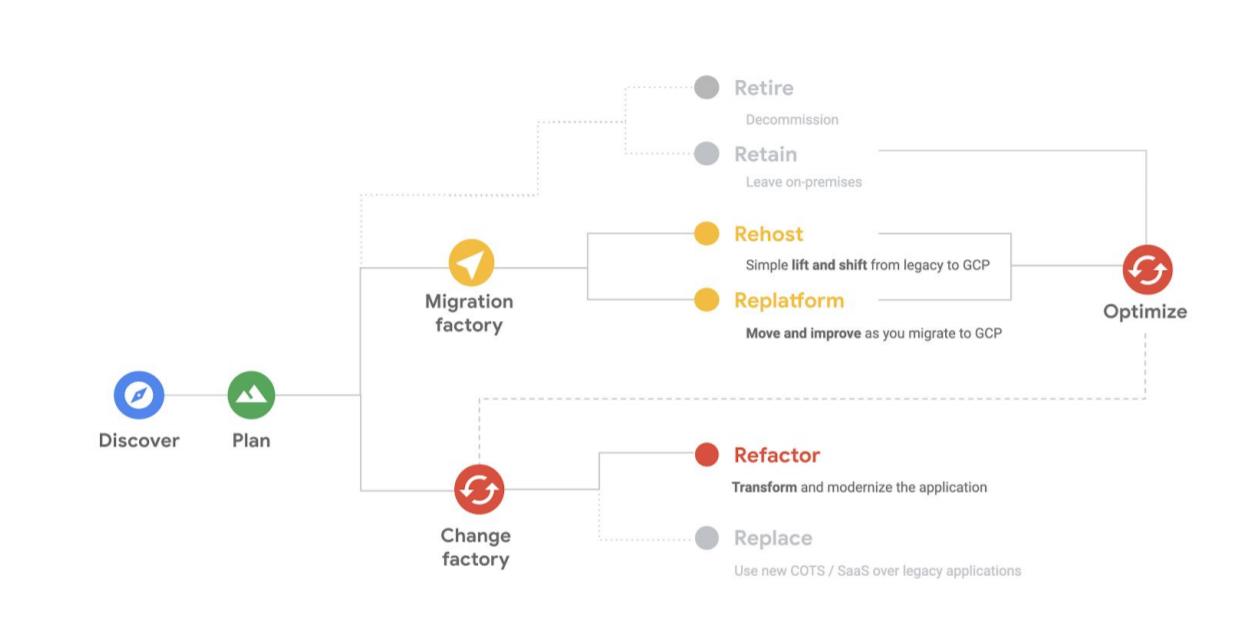
Let’s review again what some of the migration paths are, which we also outlined in Migrate Enterprise Workloads to Google Cloud.
- Lift-and-shift (rehost): “Moving out of a data center” – In a lift-and-shift migration, you move workloads from a source environment to a target environment with minor or no modifications or refactoring.
- Improve and move (Replatform): “Application Modernization” – In a move and improve migration, you modernize the workload while migrating it. In this type of migration, you modify the workloads to take advantage of cloud-native capabilities, and not just to make them work in the new environment.
- Rip and replace (Refactor): “Building in and for the Cloud” – In a rip and replace migration, you decommission an existing app and completely redesign and rewrite it as a cloud-native app
Combining cloud migration types with the Cloud Adoption Strategy maturity phases, you could summarize an approach for migrating each of your workloads as follows:
|
Tactical |
Strategic |
Transformational |
| Approach |
Lift and Shift |
Improve and Move |
Rip and Replace |
| Rehost |
Replatform |
Refactor |
| Business Objective |
Optimize costs; minimize IT disruption; achieve a scaleable, secure platform |
Maximize business value; optimize IT operations |
IT as a center of business innovation |
| Effort |
Low |
Medium |
High |
The path you take for each of your applications will differ depending on your overall strategy. Generally, large organizations lift-and-shift 70-80% of their workloads initially, focusing their transformation efforts on the areas where they can maximize impact (ex. moving a data warehouse to BigQuery, or refactoring an e-commerce platform for scale.)
Migration Phases
Looing again at the four migration phases we discussed here in Migrate Enterprise Workloads to Google Cloud, the goal with a cloud migration is to get from point A (where you are now on-prem) to point B (in the cloud).
The journey from A to B can be summarized as:
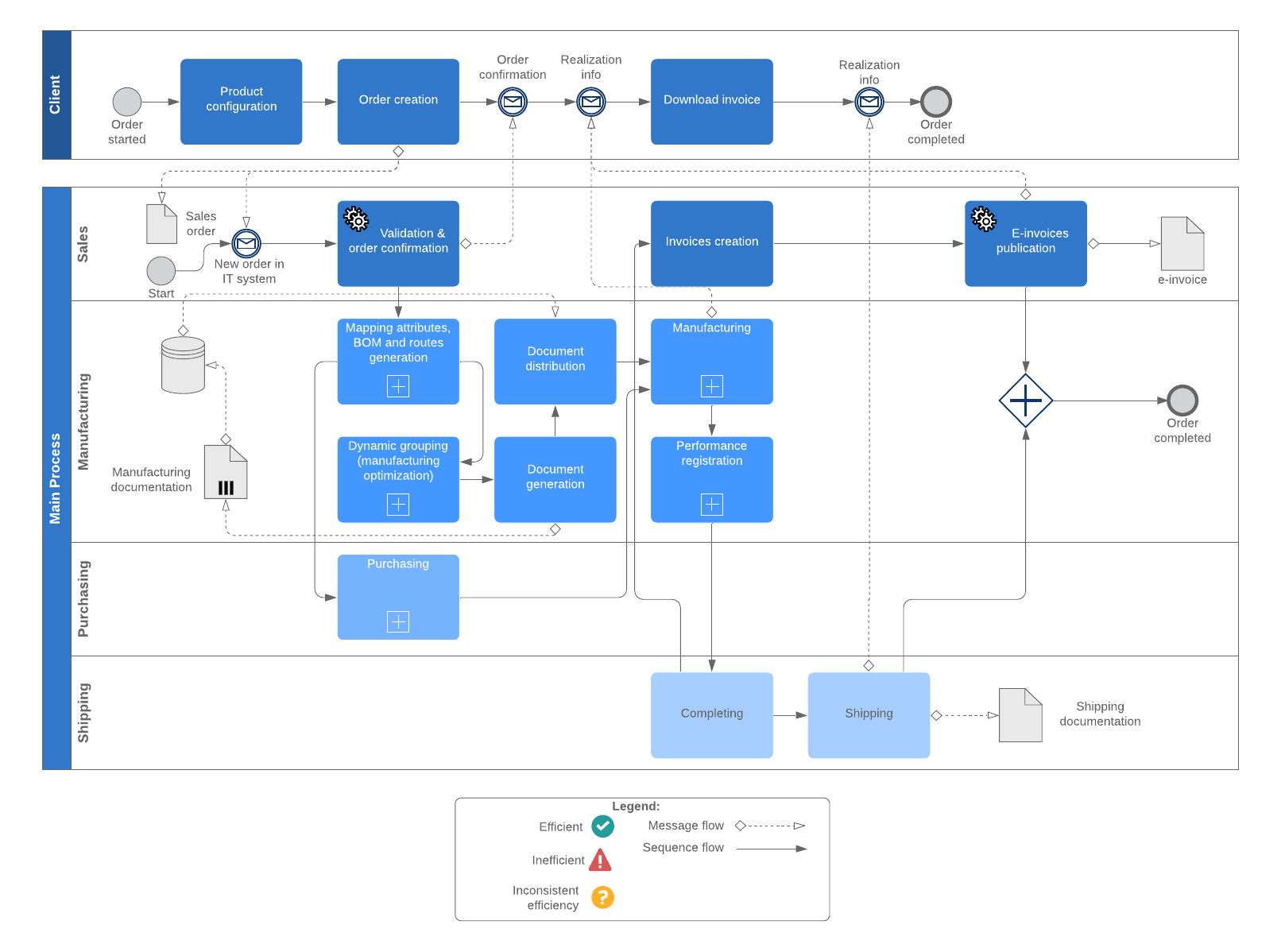
These phases can be used to build a migration approach that is an agile, scalable pipeline of workload migration. A high-level overview of the methodology is shown here:
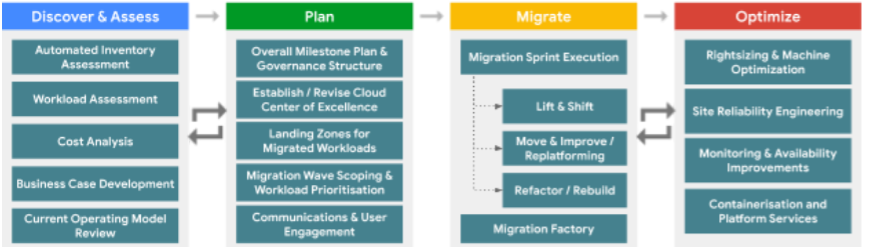
There is typically an initial sprint or series of sprints (a short, time-boxed period when a scrum team works to complete a set amount of work) of iteration through the Discover & Assess and Plan phases, in order to build a business case and a plan for the overall program. Subsequently, there you can build waves of migrations of workloads, which progress through migration using a sprint-based approach. 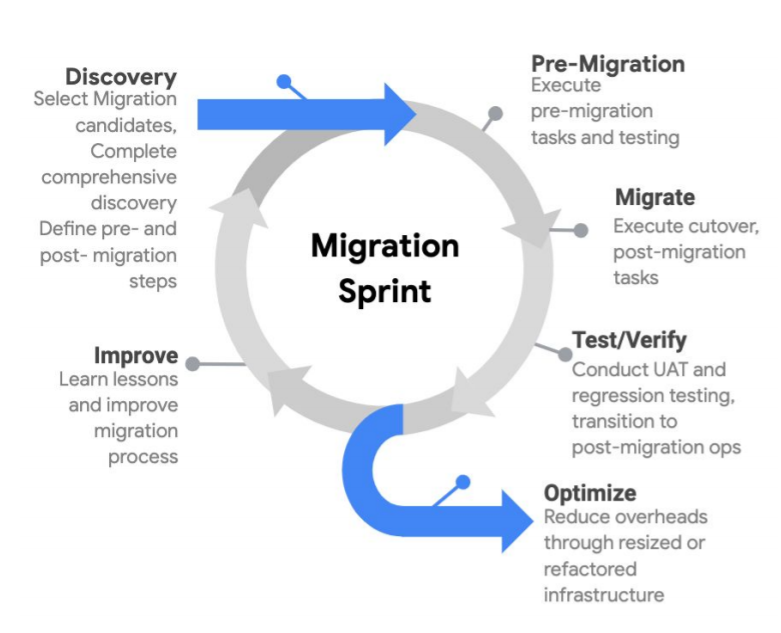
In a large-scale migration program, it’s recommended the migration sprints are managed through a Migration Factory.
Migration Factory
The migration factory is conceptualized to addresses the challenge of executing a large migration program and delivers a scalable approach aligned to the Google Cloud Adoption Framework in order to:
- Migrate and manage large volumes of systems and applications
- Initiate and drive new, cloud-native ways of working,
- Establish a new collaborative, joint teamwork model within IT and the business
Very similar to the initial Sprint, you can see that the factory is a combination of the Scrum Sprint methodology and the Cloud Adoption Framework. It is especially well-suited for large-scale migration ( 500+ servers and 200+ applications) taking a Lift and Shift (Rehost) or Improve and Move (Replatform) approach.
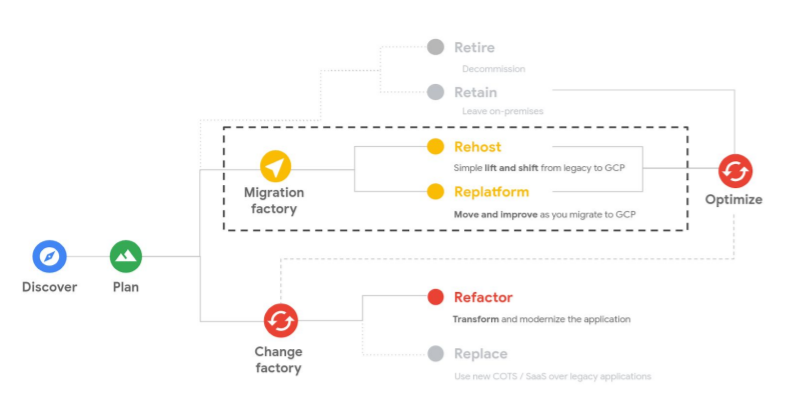
The best way to think about the factory is as an iterative approach to the framework:
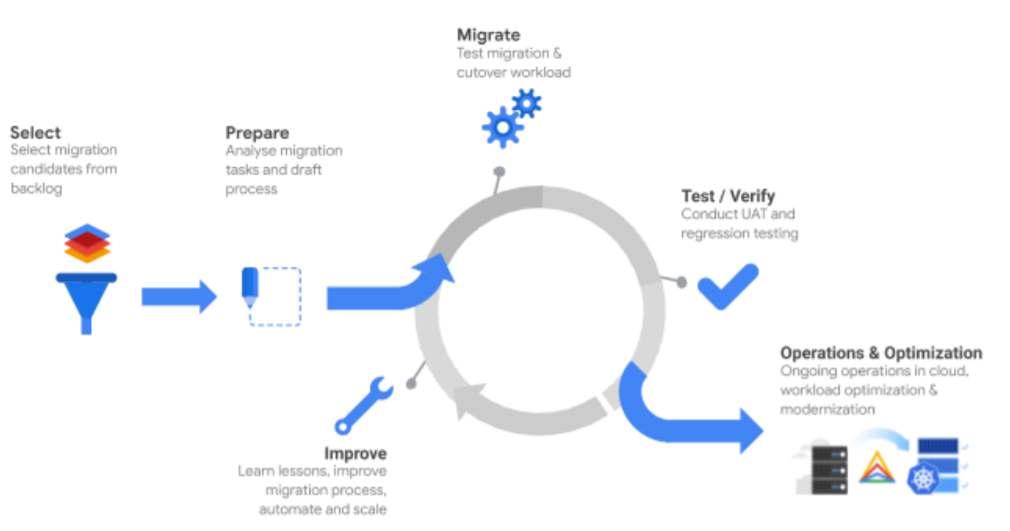
The migration factory is not a good fit when either the number of migrated workloads is too small to justify the effort building the factory or the migration approach is too individual by workload to establish an overarching holistic process.
Testing the factory
It’s important to schedule and execute some test-runs of the fully established factory including the team, the process, and all tools. Pick a couple of test cases/workloads and execute a test migration. It is recommended to repeat this exercise a couple of times until the end-to-end flow works as expected, with the predicted migration velocity and quality.
Establishing a Migration Factory
The migration factory can be divided into the three pillars of process, people, and technology; at Google, these are underpinned by the four themes of the Cloud Adoption Framework, as outlined earlier.
- Processes are the elements that are carried out by people (who develop) with their knowledge.
- People are the foundation. They are the surface and origin of the Knowledge Management, source of knowledge and actors for the next levels.
- Technology streamlines people and processes to develop and accomplish the desired output

Process
Each migration factory should follow a well-defined end-to-end process. To establish this, it’s important to analyze all possible migration tasks for all workloads necessary
- Tasks and Sub-Processes: An end-to-end process can have more than 100 individual process tasks in total. Individual tasks might have additional sub-processes and activities which should be analyzed, defined, and documented.
- Automation and economies of scale: The individual tasks are the right level of detail to start looking for automation opportunities
People
Based on an understanding of the end-to-end migration process and the total migration scope, there are two important considerations: What expertise/which teams are needed to run the process, and what is the target for migration velocity/overall scale of the program?
- Dedicated migration teams: Each team/domain should provide the right amount of skilled people and dedicate them to the migration factory. 100% dedication and assignment are strongly recommended.
- Team Capacity Planning: As individuals might get sick or be on vacation it’s essential to plan enough spare capacity
- Team Orchestration: This individual or team will oversee the process per individual migration workload, coordinate and initiate the individual tasks, manage the timely feedback, and provide regular status updates back to the migration dashboard.
Technology
There are a large number of technical tools to help to migrate workloads.
- Migration management and communication tools: A Project Management tool must be used as the single source of truth for the whole team to understand what process steps have already been completed, what’s in progress, and who needs to take the next action.
- Migration Execution Tools: Examples include Cloud Foundation Toolkit, Migrate for Compute Engine, Google BigQuery data transfer service, and CFT Scorecard.

 >
> >
> >
> >
> >
>