How OpenAI’s ChatGPT Achieves Its Power: A Look at the Hardware Behind the AI Language Model

How is ChatGPT So Powerful? A Look at the Hardware Behind OpenAI’s Latest AI Language Model
By now, you’ve probably heard of ChatGPT, the latest AI language model from OpenAI that has taken the internet by storm. With 6 billion parameters and the ability to generate coherent and convincing text on a wide range of topics, ChatGPT has been hailed as a breakthrough in natural language processing and AI in general.
But have you ever wondered how ChatGPT is able to do what it does? After all, processing language at this scale is no small feat, and it must require a lot of computing power to achieve. In this post, we’ll take a look at the hardware behind ChatGPT and try to understand what it takes to train and run such a powerful AI model.
First of all, it’s worth noting that ChatGPT is not a standalone AI system. Rather, it is part of a larger family of AI language models called GPT (short for “Generative Pre-trained Transformer”). The first GPT model was introduced by OpenAI in 2018, with 117 million parameters, and subsequent versions have increased in size and complexity, culminating in ChatGPT with its 6 billion parameters.
So, how is ChatGPT trained? According to OpenAI, the model is fine-tuned from a larger pre-trained model using a technique called unsupervised learning. Essentially, the model is fed a massive amount of text from the internet and other sources, and it learns to predict the next word or sentence based on the context. Over time, the model gets better and better at this task, and it becomes able to generate text on its own that is coherent and relevant to the input prompt.
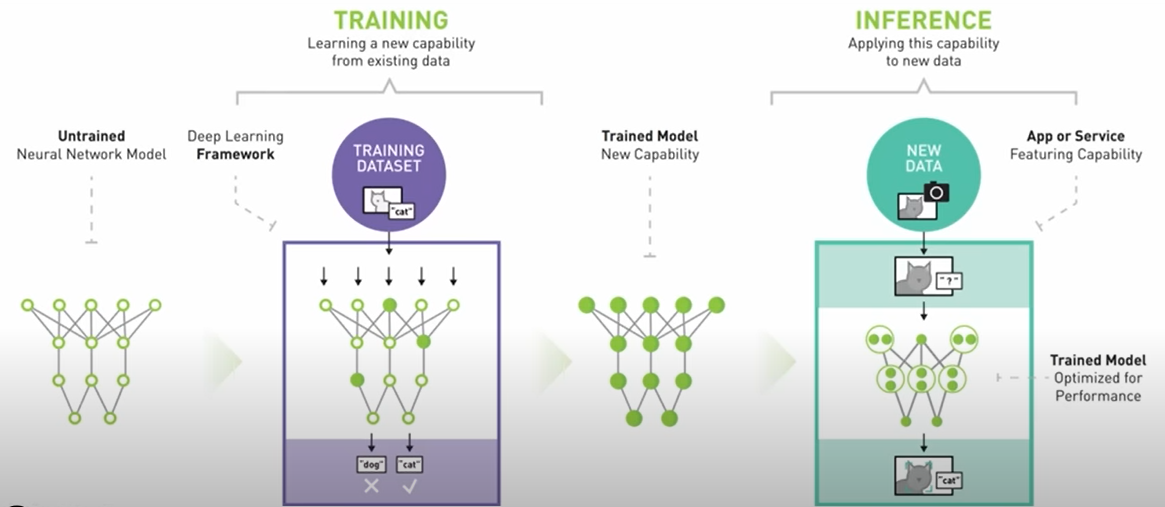
Source: Nvidia
However, training a model like ChatGPT requires a massive amount of computing power. OpenAI has not disclosed the exact hardware used to train ChatGPT, but we can make some educated guesses based on previous information about their AI infrastructure.
For example, the previous GPT-3 model, which has “only” 175 billion parameters, was trained on a supercomputer with 285,000 CPU cores and 10,000 Nvidia V100 GPUs provided by Microsoft. This hardware setup allowed OpenAI to train the model in a relatively short amount of time, but it also came with a significant cost, both in terms of money and energy consumption.

Given that ChatGPT has fewer parameters than GPT-3 but still requires a lot of computing power to train, it’s likely that OpenAI used a similar or even more powerful hardware setup for this model. One possibility is that they used Nvidia A100 GPUs, which are the latest and most powerful GPUs from Nvidia as of early 2022. These GPUs offer significant speedups over the previous generation, and they are designed specifically for AI workloads like training and inference.
Another possibility is that OpenAI used AMD EPYC CPUs in conjunction with the Nvidia GPUs. AMD EPYC CPUs are also designed for server workloads and offer high performance and efficiency for AI tasks. Combining these CPUs with Nvidia GPUs can lead to even faster training times and better overall performance for AI models.
Of course, these are just educated guesses, and we won’t know for sure what hardware OpenAI used for ChatGPT unless they release more information about their AI infrastructure. However, one thing is clear: training and running powerful AI models like ChatGPT requires a lot of computing power, and it’s only going to get more demanding as AI models continue to increase in size and complexity.
Next, let’s take a closer look at the hardware behind ChatGPT and try to make a more informed guess about how we have come to some of these hardware predictions.
The Hardware Behind ChatGPT
The first step in understanding the hardware used to train ChatGPT is to look at the timeline. OpenAI confirmed that ChatGPT was fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022. This provides us with a time frame to work with, and we can assume that the model was trained on hardware that was available at that time.
Next, we need to identify the type of hardware used. We know that ChatGPT was trained on Microsoft Azure infrastructure, and in June 2021, Microsoft announced the availability of Nvidia A100 GPU clusters to its Azure customers. Therefore, it’s reasonable to assume that ChatGPT was trained on Nvidia A100 GPUs.
But how many A100 GPUs were used? To answer that question, we need to look at the specifications of the A100. The A100 is based on the GA100 chip, which packs 54.2 billion transistors into a 826 millimeter squared large die produced by TSMC in a 7 nanometer node. Tensor performance gets another huge bump to over 300 teraflops, 2.5 times the performance of a single V100 GPU!

However, it’s unlikely that Microsoft replaced all 10,000 Volta GPUs in their supercomputer with 10,000 Ampere GPUs. ChatGPT is a more streamlined machine learning model, and it wouldn’t be a cost-effective decision to use Ampere, which is so much faster.
In October of 2021, before the training of ChatGPT started, Nvidia and Microsoft announced a new AI supercomputer they used to train a new and extremely large neural network called Megatron-Turning NLG. This neural network has 530 billion parameters and was trained on 560 Nvidia DGX A100 servers, each containing 8 Ampere A100 GPUs. Therefore, it’s safe to assume that ChatGPT was trained on a similar system to Megatron-Turing NLG, using multiple clusters of Nvidia DGX or HGX A100 servers.
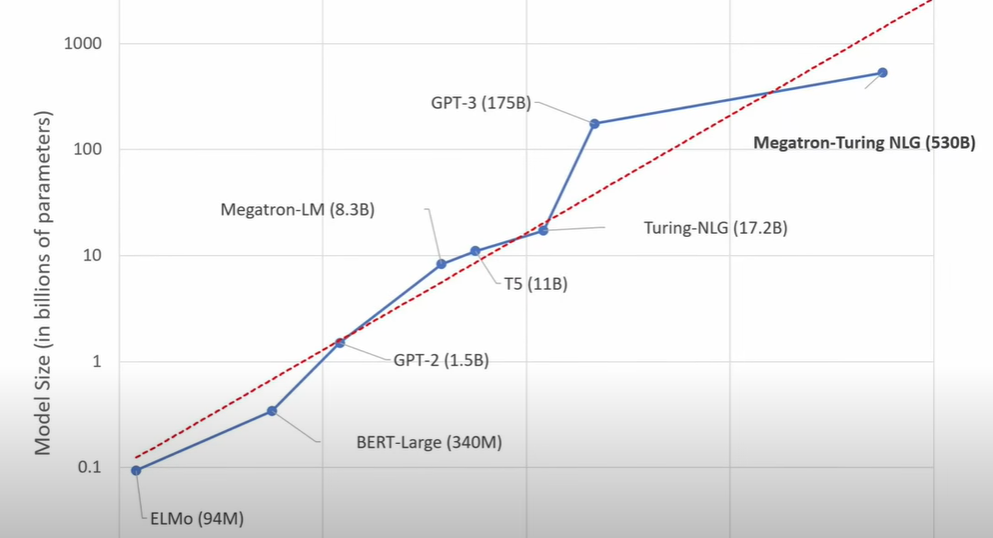
Using this information, we can make an educated guess that ChatGPT was trained on 1,120 AMD EPYC 7742 server CPUs with over 70,000 CPU cores and 4,480 Nvidia A100 GPUs. This would provide close to 1.4 exaflops of FP16 tensor core performance. While we can’t confirm these specifications without official confirmation, it’s a reasonable deduction based on the available information.

Now, let’s take a look at the hardware used for ChatGPT inference. According to statements from Microsoft and OpenAI, ChatGPT inference is running on Microsoft Azure servers, and a single Nvidia DGX or HGX A100 instance is likely enough to run inference for ChatGPT. However, at the current scale, it would require well over 3,500 Nvidia A100 servers with close to 30,000 A100 GPUs to provide inference for ChatGPT.
This massive amount of hardware is required to keep the service running and costs between $500,000 to $1 million dollars per day. While the current level of demand for ChatGPT makes it worth it for Microsoft and OpenAI, it’s unlikely that such a system can stick to a free-to-use model in the long run unless better and more efficient hardware reduces the cost of running inference at scale.
With the future of AI looking bright, there’s a lot of new hardware on the way, and the entire hardware industry is starting to shift its focus on architectures specifically designed to accelerate AI workloads. In only a few years’ time, training a model like ChatGPT will be part of your average machine learning course in college, and running inference will be done on a dedicated AI engine inside of your smartphone.
As AI progress is hardware-bound, and the hardware is just getting started, we can expect fierce competition between companies like Nvidia and AMD. The upcoming CDNA3 based MI300 GPUs from AMD will provide strong competition for NVIDIA, especially when it comes to AI workloads.
References
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.