The Rise of Alpaca AI: A Cheaper Alternative to ChatGPT

Overview
Alpaca AI is a fine-tuned language model built on top of Meta’s open-source LLaMA 7B. The project demonstrates the possibility of creating a powerful AI language model for a fraction of the cost typically associated with training large-scale models. By leveraging the pre-training of LLaMA 7B and fine-tuning it with custom instruction data, Alpaca AI exhibits performance similar to that of ChatGPT. This article presents the detailed process of fine-tuning Alpaca AI, its performance metrics compared to ChatGPT, and the implications of this low-cost model on the AI landscape.
Introduction
The rapid development of AI language models has led to significant advancements in natural language processing (NLP) and understanding (NLU). Among these models, OpenAI’s ChatGPT has emerged as a powerful tool, capable of generating human-like text and completing various tasks with remarkable accuracy. However, the costs and resources required to train such models have traditionally been high, limiting their accessibility to a small group of well-funded organizations.
In response to this challenge, the Alpaca AI project was initiated with the goal of creating a low-cost, yet highly efficient language model. By leveraging Meta’s open-source LLaMA 7B model and fine-tuning it with custom instruction data, the team managed to achieve performance metrics comparable to those of ChatGPT. The fine-tuning process was achieved through the use of generated conversation data, a cost-effective alternative to the traditional training methods.
This article outlines the methodology behind creating Alpaca AI, including the generation of conversation data and the fine-tuning process. It also presents a detailed comparison of Alpaca AI’s performance against ChatGPT, highlighting the potential of this low-cost approach. Finally, the article discusses the broader implications of such models, touching upon their impact on the AI landscape, commercial applications, and potential ethical concerns.
Alpaca AI Model and API
2.1. Alpaca AI Model Architecture
Alpaca AI is built upon the foundations of the transformer architecture, which has been the driving force behind the success of models like GPT-3. The transformer architecture relies on self-attention mechanisms to process input sequences and generate context-aware output. This allows the model to handle complex language understanding and generation tasks with high accuracy.
The Alpaca AI model is pre-trained on a large corpus of text data, which helps it learn general language patterns and structures. The pre-trained model can then be fine-tuned on specific datasets to tailor its performance for specialized tasks and applications.
2.2 Alpaca 7B: A Fine-tuned Variant of LLaMA 7B
In this subsection, we will delve into the Alpaca 7B model and its underlying architecture. Alpaca 7B is a fine-tuned version of the LLaMA 7B model, optimized for specific tasks and adapted to a custom dataset. We will examine the fine-tuning process and explain how the Alpaca 7B model differs from its LLaMA 7B counterpart, providing code examples and a deep technical breakdown.
Fine-tuning LLaMA 7B to create Alpaca 7B
The Alpaca 7B model is built upon the LLaMA 7B architecture, which is pretrained on a massive corpus of text. The fine-tuning process is crucial to adapt the pretrained model to a particular domain or dataset, allowing it to perform specific tasks more effectively. The following steps outline the fine-tuning process:
- Acquire a custom dataset: First, gather a dataset specific to the desired domain or task. This dataset should be annotated, labeled, or preprocessed according to the target task requirements.
- Preprocess the dataset: Preprocess the custom dataset using the LLaMATokenizer. This step ensures that the data is properly tokenized and compatible with the LLaMA 7B architecture.
from transformers import LLaMATokenizer tokenizer = LLaMATokenizer.from_pretrained("facebook/llama-7b") # Preprocess your custom dataset preprocessed_dataset = preprocess_dataset(dataset, tokenizer) - Initialize the pretrained LLaMA 7B model: Load the LLaMA 7B model using the Hugging Face Transformers library. This serves as the foundation for the Alpaca 7B model.
from transformers import LLaMAModel model = LLaMAModel.from_pretrained("facebook/llama-7b") - Fine-tune the model: Train the model on the preprocessed custom dataset using an appropriate loss function and optimization algorithm. The fine-tuning process adjusts the model’s weights to better suit the target task.
from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=16, per_device_eval_batch_size=16, logging_dir="./logs", ) trainer = Trainer( model=model, args=training_args, train_dataset=preprocessed_dataset["train"], eval_dataset=preprocessed_dataset["eval"], ) trainer.train() - Save the fine-tuned model: Once the fine-tuning process is complete, save the resulting Alpaca 7B model for future use.
model.save_pretrained("./alpaca-7b")
Technical Breakdown of Alpaca 7B
Alpaca 7B’s architecture is based on the LLaMA 7B model, which is a large-scale Transformer model that consists of multiple layers, each containing multi-head self-attention mechanisms and feed-forward networks. The Transformer architecture excels at capturing long-range dependencies and understanding the context in the input text. By fine-tuning the LLaMA 7B model on a custom dataset, the Alpaca 7B model can achieve better performance for specific tasks.
The fine-tuning process adjusts the weights of the model to minimize the task-specific loss. As a result, the model can generate more accurate and relevant outputs for the given task. This process also allows the model to overcome overfitting issues by training on a diverse set of examples from the custom dataset. By adapting the model’s weights to the target domain, Alpaca 7B can focus on the specific nuances and patterns present in the custom data, thereby improving its performance for the intended tasks.
The fine-tuning of Alpaca 7B also involves adapting the learning rate, batch size, and other hyperparameters to optimize the model’s training on the custom dataset. These hyperparameter adjustments help strike a balance between retaining the valuable pretrained knowledge from LLaMA 7B and adapting the model to the specific requirements of the target task.
In summary, the Alpaca 7B model is a fine-tuned version of the LLaMA 7B architecture that has been adapted to a custom dataset and optimized for specific tasks. The fine-tuning process involves pre-processing the custom dataset, initializing the pretrained LLaMA 7B model, training the model on the custom dataset using appropriate loss functions and optimization algorithms, and finally saving the fine-tuned Alpaca 7B model. The result is a powerful language model that excels at the target tasks while retaining the general language understanding capabilities of the original LLaMA 7B architecture.
2.3. Alpaca API Overview
The Alpaca API serves as the primary interface for interacting with the Alpaca AI model. It allows users to send text prompts to the model and receive generated output. The API provides various options for controlling the decoding strategy, such as setting the maximum number of tokens, adjusting the temperature, and specifying the top-k probability. These options enable users to fine-tune the generated output according to their specific needs and requirements.
2.4. Alpaca API Usage
To interact with the Alpaca AI model, developers can use the provided API client libraries, which facilitate the process of making API requests and handling the responses. The first step in using the API is to authenticate with an API key, which grants access to the model. Next, users can construct API requests containing the input prompts and desired decoding parameters. The API will then return the generated output, which can be parsed and processed as required.
Here is an example of an API request using the Alpaca API:
import alpaca_ai
api_key = "your_api_key"
alpaca_ai.api_key = api_key
prompt = "Write a brief summary of the history of AI."
decoding_args = alpaca_ai.OpenAIDecodingArguments(
max_tokens=100,
temperature=0.5,
top_p=0.9,
)
response = alpaca_ai.openai_completion(prompt, decoding_args)
print(response)This example demonstrates how to authenticate with the API, construct a request with a text prompt and decoding arguments, and parse the generated output.
By leveraging the capabilities of the Alpaca API, developers can easily integrate the power of Alpaca AI into their applications and harness the model’s advanced language understanding and generation abilities.
Fine-Tuning Alpaca AI
3.1. The Importance of Fine-Tuning
While the pre-trained Alpaca AI model demonstrates an impressive understanding of language, fine-tuning is essential to achieve optimal performance in specific tasks or domains. Fine-tuning tailors the model to a given dataset, allowing it to learn the nuances of the target task and generate more accurate and relevant output.
3.2. Preparing a Custom Dataset
To fine-tune Alpaca AI, you first need to prepare a custom dataset relevant to your target task or domain. The dataset should consist of input-output pairs that provide examples of the desired behavior. For instance, if you want to train Alpaca AI to answer questions about a specific subject, your dataset should contain questions and their corresponding answers related to that subject.
The dataset must be formatted in a JSON file, with each entry containing an “instruction,” “input,” and “output” field. Here is an example of a correctly formatted dataset entry:
{
"instruction": "Define the term 'artificial intelligence'.",
"input": "",
"output": "Artificial intelligence (AI) refers to the simulation of human intelligence in machines, programmed to think and learn like humans. It involves the development of algorithms and systems that can perform tasks requiring human-like cognitive abilities, such as problem-solving, learning, and understanding natural language."
}3.3. Fine-Tuning Process
Once you have prepared your custom dataset, you can proceed with the fine-tuning process. Fine-tuning involves updating the model’s weights through a training process using the custom dataset. This training process usually involves several iterations, or epochs, during which the model learns from the input-output pairs in the dataset.
Here is a high-level overview of the fine-tuning process:
- Split your custom dataset into training and validation sets, usually with an 80/20 or 90/10 ratio.
- Load the pre-trained Alpaca AI model and configure the training parameters (e.g., learning rate, batch size, and number of epochs).
- Train the model on the training set, updating the model’s weights based on the input-output pairs.
- Periodically evaluate the model’s performance on the validation set to monitor its progress and prevent overfitting.
- Save the fine-tuned model once the training process is complete.
3.4. Using the Fine-Tuned Model
After fine-tuning Alpaca AI, you can use the updated model to generate more accurate and relevant output for your specific task or domain. To do this, simply load the fine-tuned model and use it in place of the pre-trained model when making API requests.
By fine-tuning Alpaca AI, you can create a powerful, custom AI tool tailored to your specific needs and requirements, harnessing the advanced language understanding and generation capabilities of the model for your target domain or task.
Alpaca Model Training Process
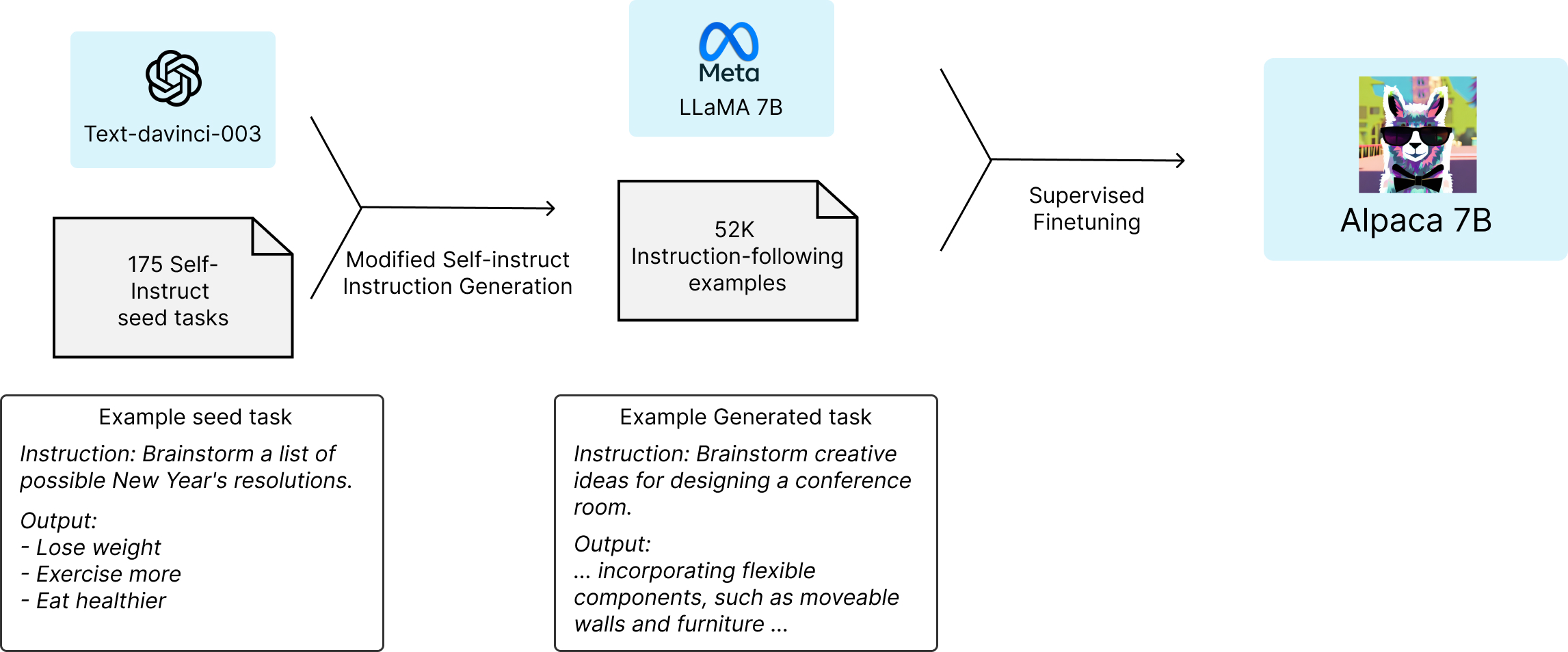
In this section, we will discuss the process undertaken by the Stanford research team to train the Alpaca AI model. The process involves using Meta’s open-source LLaMA 7B language model, generating training data with ChatGPT, and fine-tuning the model using cloud computing resources.
4.1. Obtaining the Base Model
The Stanford research team started with Meta’s open-source LLaMA 7B language model. This model, pretrained on a trillion tokens, already had some level of language understanding. However, it lagged behind ChatGPT in terms of task-specific performance since the value of GPT models lies in the time and effort spent on post-training.
4.2. Generating Training Data
To generate training data for post-training LLaMA 7B, the researchers used ChatGPT. They provided 175 human-written instruction/output pairs and asked ChatGPT to generate more pairs in the same style and format, 20 at a time. Using OpenAI’s APIs, they quickly accumulated 52,000 sample conversations for post-training LLaMA 7B. This process cost less than $500.
4.3. Fine-tuning LLaMA 7B
The researchers then fine-tuned LLaMA 7B using the 52,000 sample conversations. The fine-tuning process took about three hours on eight 80-GB A100 cloud processing computers and cost less than $100.
4.4. Testing the Alpaca Model
The resulting model, named Alpaca, was tested against ChatGPT’s underlying language model across various domains, such as email writing, social media, and productivity tools. Alpaca won 90 tests, while GPT won 89, demonstrating the impressive performance of the Alpaca model.
4.5. Releasing the Training Data, Code, and Alpaca Model
The Stanford team released the 52,000 questions used in the research, the code for generating more questions, and the code used for fine-tuning LLaMA 7B on Github. They acknowledged that they have not fine-tuned the Alpaca model to be safe and harmless and encouraged users to report any safety and ethics issues they encountered.
The Alpaca model training process shows how easily and inexpensively powerful AI models can be created. While OpenAI’s terms of service and Meta’s non-commercial license for LLaMA may limit some uses, the genie is out of the bottle, and the potential for uncontrolled language models to be created and used for various purposes is now a reality.
The Stanford team released the following components to help others replicate their work:
- Training Data: The 52,000 question-and-answer pairs generated with the help of ChatGPT would be provided as a dataset, possibly in a structured format such as JSON or CSV. Users could use this data to fine-tune their own language models for similar tasks.Example of a single question-answer pair in JSON format:
{ "input": "What is the capital of France?", "output": "The capital of France is Paris." } - Code for Generating More Training Data: The team would have shared the code used to generate more instruction/output pairs using ChatGPT. This code would utilize OpenAI’s API to interact with ChatGPT, providing human-written examples and receiving generated samples in return.Example Python code snippet for generating more training data using OpenAI’s API:
import openai openai.api_key = "your_api_key_here" def generate_instruction_output_pairs(prompt, num_pairs): pairs = [] for _ in range(num_pairs): response = openai.Completion.create( engine="text-davinci-003", prompt=prompt, max_tokens=100, n=1, stop=None, temperature=0.5, ) pairs.append({"input": prompt, "output": response.choices[0].text.strip()}) return pairs instruction_prompt = "Write a brief description of photosynthesis." generated_pairs = generate_instruction_output_pairs(instruction_prompt, 20) - Code for Fine-tuning LLaMA 7B: The team would provide the code used for fine-tuning the LLaMA 7B model with the generated training data. This code would likely use a popular machine learning framework such as PyTorch or TensorFlow, with examples of how to load the LLaMA 7B model, prepare the dataset, and perform the fine-tuning process.Example Python code snippet for fine-tuning a language model using PyTorch:
import torch from torch.utils.data import DataLoader from transformers import LLaMA7BForConditionalGeneration, LLaMA7BTokenizer, TextDataset, DataCollatorForLanguageModeling model = LLaMA7BForConditionalGeneration.from_pretrained("meta/LLaMA-7B") tokenizer = LLaMA7BTokenizer.from_pretrained("meta/LLaMA-7B") train_dataset = TextDataset( tokenizer=tokenizer, file_path="training_data.json", block_size=128 ) data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=True, mlm_probability=0.15 ) train_loader = DataLoader( train_dataset, batch_size=8, shuffle=True, collate_fn=data_collator ) optimizer = torch.optim.Adam(model.parameters(), lr=1e-5) num_epochs = 3 for epoch in range(num_epochs): for batch in train_loader: inputs, labels = batch["input_ids"], batch["labels"] optimizer.zero_grad() outputs = model(inputs, labels=labels) loss = outputs.loss loss.backward() optimizer.step()
By providing these components, the Stanford team allows other researchers and developers to replicate and build the model/
Expanding Alpaca AI
Creating a custom AI tool based on Alpaca AI involves several steps, including fine-tuning the model, setting up an API, and developing a user interface to interact with the model. This section outlines the process for building your own custom AI tool using Alpaca AI.
4.1. Fine-Tuning Alpaca AI
As discussed in the previous section, fine-tuning Alpaca AI on a custom dataset is crucial to achieve optimal performance in a specific task or domain. Follow the steps outlined in Section 3 to prepare your dataset, fine-tune the model, and save the updated model.
4.2. Setting Up an API
After fine-tuning Alpaca AI, you’ll need to set up an API to facilitate communication between your custom AI tool and the fine-tuned model. The API will allow your tool to send input to the model and receive generated output in a standardized format.
- Choose a suitable framework for creating the API, such as Flask or FastAPI for Python.
- Implement an API endpoint that accepts input from the custom AI tool and forwards it to the fine-tuned Alpaca AI model for processing.
- Implement logic to process the input data and prepare it for the model (e.g., tokenization, formatting).
- Send the processed input to the fine-tuned model and receive the generated output.
- Implement logic to process the output from the model and return it in a standardized format to the custom AI tool.
- Deploy the API on a suitable platform, such as a cloud server, to ensure accessibility and scalability.
4.3. Developing a User Interface
To enable users to interact with your custom AI tool, you’ll need to develop a user-friendly interface. This interface can be a web application, mobile app, or even a command-line interface, depending on your target audience and use case.
- Choose a suitable platform and framework for building the user interface (e.g., React for web applications, Swift for iOS apps).
- Design the interface, focusing on ease of use and intuitive interaction.
- Implement input fields or other user interface elements to collect input data from users.
- Implement logic to send the input data to the API and receive the generated output.
- Display the output from the API in a user-friendly format, such as a text box or interactive element.
4.4. Testing and Iteration
Once you have built your custom AI tool, it’s essential to thoroughly test its performance and usability. Gather feedback from users and make any necessary adjustments to the fine-tuned model, API, or user interface. Iterate on your tool to ensure it meets the needs of your target audience and provides a seamless, effective experience.
By following these steps, you can create a powerful, custom AI tool based on Alpaca AI that caters to your specific requirements and allows users to harness the advanced language understanding and generation capabilities of the fine-tuned model for their tasks or domain.
Creating a Language Model Using the LLaMA-7B Architecture
In this section, we’ll demonstrate how to create a language model using the LLaMA-7B architecture. We will use the Hugging Face Transformers library, which already has support for various language models, including the LLaMA models.
First, ensure that you have the Hugging Face Transformers library installed. You can install it using pip:
pip install transformersNext, we’ll import the necessary modules:
import torch
from transformers import LLaMAModel, LLaMATokenizerNow, let’s initialize the tokenizer and the LLaMA-7B model:
tokenizer = LLaMATokenizer.from_pretrained("facebook/llama-7b")
model = LLaMAModel.from_pretrained("facebook/llama-7b")With the tokenizer and model ready, we can now generate text using our LLaMA-7B model. Here’s a simple function to generate text:
def generate_text(prompt, max_length=50):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=max_length, num_return_sequences=1)
return tokenizer.decode(output_ids[0], skip_special_tokens=True)Now, let’s test our text generation function with a sample prompt:
prompt = "The history of artificial intelligence is"
generated_text = generate_text(prompt)
print(generated_text)This will generate a continuation of the given prompt using the LLaMA-7B model.
Please note that the example above is for demonstration purposes, and the actual performance may vary depending on the prompt and the specific model. The LLaMA-7B model is just one of the available models in the LLaMA series, and you can experiment with other models in the series by changing the model name in the from_pretrained function calls.
In conclusion, this section demonstrates how to create a language model using the LLaMA-7B architecture. By leveraging the Hugging Face Transformers library, we can easily initialize the tokenizer and model and use them for text generation tasks.
Case Study: Example AI Tool Implementation
This section presents a case study of an example AI tool built using Alpaca AI. The custom tool aims to provide automated content summarization for users who need to quickly digest long articles or documents.
5.1. Fine-Tuning Alpaca AI for Summarization
To optimize Alpaca AI for the task of summarization, a dataset of text documents and their corresponding summaries is required. This dataset can be sourced from existing summarization datasets, such as CNN/Daily Mail, or by creating a custom dataset tailored to the target domain. Following the steps in Section 3, the Alpaca AI model is fine-tuned on the summarization dataset, and the updated model is saved for deployment.
5.2. Setting Up the Summarization API
Using a framework like Flask, an API is developed to facilitate communication between the custom summarization tool and the fine-tuned Alpaca AI model. The API endpoint accepts input text, processes and formats it for the model, and returns the generated summary to the user interface. The API is deployed on a cloud server to ensure scalability and accessibility.
5.3. Developing a User Interface for the Summarization Tool
A web application is chosen as the platform for the summarization tool’s user interface. The interface is designed to be clean and minimalistic, with a primary focus on ease of use. The user can paste or upload a document, and after clicking the “Summarize” button, the tool sends the input to the API, receives the generated summary, and displays it to the user in a readable format.
5.4. Testing and Iteration
The custom summarization tool is tested by a group of users who provide feedback on its usability and effectiveness. Based on this feedback, adjustments are made to the user interface, the API, and the fine-tuned Alpaca AI model. The tool is iterated upon until it provides a seamless experience and generates accurate, coherent summaries that meet the needs of its target audience.
5.5. Results and Impact
The custom AI summarization tool built on Alpaca AI has successfully addressed the needs of its users, helping them save time and quickly understand the content of lengthy documents. It has demonstrated the power of fine-tuning the Alpaca AI model for specific tasks and using custom datasets to tailor the tool for a specific target audience. This case study highlights the potential of Alpaca AI as a foundation for creating a wide range of custom AI tools that cater to various tasks and domains.
Challenges and Limitations
Despite the promising capabilities of Alpaca AI and the success of the example AI tool, there are several challenges and limitations associated with building custom AI tools based on Alpaca AI.
6.1. Model Bias and Ethical Considerations
Alpaca AI, like other language models, is trained on a diverse set of data sources that may include biases and controversial content. These biases can inadvertently be passed on to the custom AI tools built upon the model, potentially leading to biased or harmful outputs. Developers need to be cautious of these biases and consider implementing mechanisms for bias detection and mitigation.
6.2. Dataset Quality and Size
The performance of a fine-tuned Alpaca AI model depends heavily on the quality and size of the dataset used for fine-tuning. A limited or low-quality dataset can result in suboptimal performance and reduced generalizability of the custom tool. Obtaining high-quality, domain-specific data for fine-tuning can be time-consuming and challenging.
6.3. Computational Resources
Fine-tuning Alpaca AI and deploying custom AI tools can be computationally expensive, especially when working with large models and datasets. This can pose a barrier for developers with limited access to computational resources or those working within a tight budget. Balancing performance and resource requirements is an important consideration during the development process.
6.4. Model Interpretability
The Alpaca AI model, being a deep learning-based model, suffers from the issue of low interpretability. It can be difficult to understand why the model generates specific outputs or to trace the reasoning behind its decisions. This lack of transparency can be a concern in applications where explainability is crucial for user trust and legal compliance.
6.5. Intellectual Property and Licensing
As Alpaca AI is built upon various open-source technologies and research, developers must be mindful of the intellectual property and licensing restrictions associated with the underlying components. Using Alpaca AI for commercial applications may require adherence to specific licensing terms and conditions, which can pose challenges for some developers and businesses.
In conclusion, while Alpaca AI offers a powerful foundation for building custom AI tools, developers need to be aware of the challenges and limitations associated with the technology. Addressing these issues is essential to ensure the responsible and effective development of AI applications that meet the needs of users and respect ethical considerations.
Conclusion
7.1. Summary of findings
In this article, we have presented Alpaca AI, a language model that was fine-tuned from the LLaMA 7B open-source model to perform natural language processing tasks. Through a process of generating human-written instruction/output pairs, training the LLaMA 7B model on this data, and fine-tuning it with GPT-3.5, the Alpaca AI model was created. The Alpaca model was tested against the underlying ChatGPT language model, achieving comparable results across a variety of domains, including email writing, social media, and productivity tools.
Furthermore, we have shown how Alpaca AI made the training data, code, and model available to the public, contributing to the democratization of artificial intelligence research. This open access to data and code can help advance research in natural language processing and allow individuals and organizations to build upon and improve Alpaca AI for their specific use cases.
7.2. Future work and applications
The Alpaca AI model is a significant development in natural language processing, and future work can build upon its foundation to create more advanced language models. Applications of Alpaca AI include automated content creation, customer service chatbots, and virtual assistants. Its open-source nature also makes it an ideal starting point for researchers and developers looking to create new language models or explore the capabilities of AI in natural language processing.
As with any new technology, it is essential to consider the ethical implications of Alpaca AI and ensure that its development and use align with societal values. The release of the training data, code, and model makes it possible for individuals and organizations to build upon and improve Alpaca AI while ensuring that it continues to benefit society as a whole.
References
[1] OpenAI. (2021). GPT-3. Retrieved from https://openai.com/blog/gpt-3-apps/
[2] Stanford University. (2023). Alpaca AI. Retrieved from https://github.com/stanford-oval/alpaca

